Details
-
Bug
-
Status: Resolved
-
 Critical
Critical
-
Resolution: Fixed
-
2.1.1, 2.1.2
-
None
Description
The pdf version of this issue with high-quality figures is available at https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/report/OOM-TaskMemoryManager.pdf.
[Abstract]
I recently encountered an OOM error in a PageRank application (org.apache.spark.examples.SparkPageRank). After profiling the application, I found the OOM error is related to the memory contention in shuffle spill phase. Here, the memory contention means that a task tries to release some old memory consumers from memory for keeping the new memory consumers. After analyzing the OOM heap dump, I found the root cause is a memory leak in TaskMemoryManager. Since memory contention is common in shuffle phase, this is a critical bug/defect. In the following sections, I will use the application dataflow, execution log, heap dump, and source code to identify the root cause.
[Application]
This is a PageRank application from Spark’s example library. The following figure shows the application dataflow. The source code is available at [1].
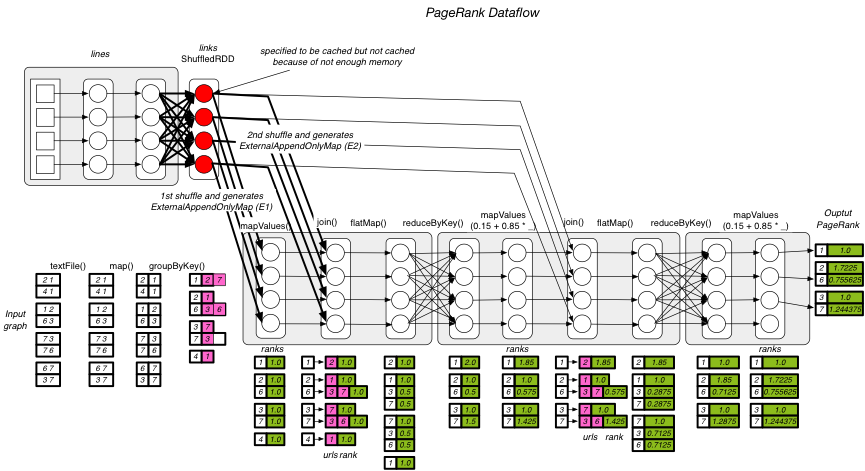
[Failure symptoms]
This application has a map stage and many iterative reduce stages. An OOM error occurs in a reduce task (Task-28) as follows.
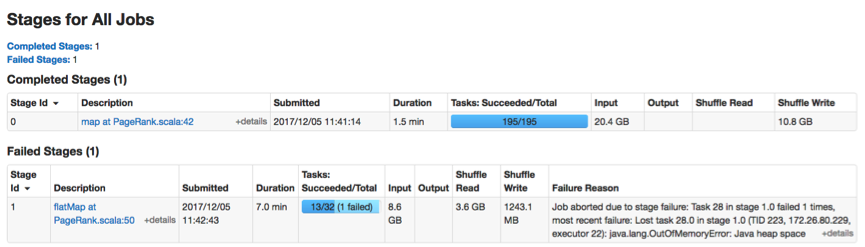

[OOM root cause identification]
Each executor has 1 CPU core and 6.5GB memory, so it only runs one task at a time. After analyzing the application dataflow, error log, heap dump, and source code, I found the following steps lead to the OOM error.
=> The MemoryManager found that there is not enough memory to cache the links:ShuffledRDD (rdd-5-28, red circles in the dataflow figure).

=> The task needs to shuffle twice (1st shuffle and 2nd shuffle in the dataflow figure).
=> The task needs to generate two ExternalAppendOnlyMap (E1 for 1st shuffle and E2 for 2nd shuffle) in sequence.
=> The 1st shuffle begins and ends. E1 aggregates all the shuffled data of 1st shuffle and achieves 3.3 GB.

=> The 2nd shuffle begins. E2 is aggregating the shuffled data of 2nd shuffle, and finding that there is not enough memory left. This triggers the memory contention.

=> To handle the memory contention, the TaskMemoryManager releases E1 (spills it onto disk) and assumes that the 3.3GB space is free now.

=> E2 continues to aggregates the shuffled records of 2nd shuffle. However, E2 encounters an OOM error while shuffling.


[Guess]
The task memory usage below reveals that there is not memory drop down. So, the cause may be that the 3.3GB ExternalAppendOnlyMap (E1) is not actually released by the TaskMemoryManger.
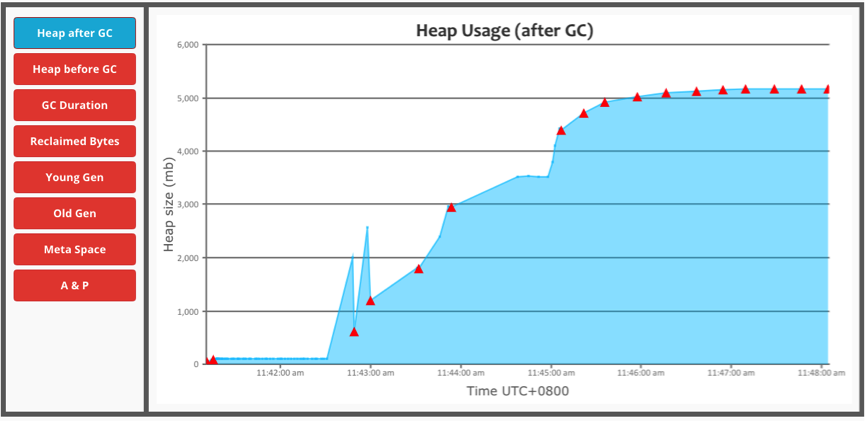
[Root cause]
After analyzing the heap dump, I found the guess is right (the 3.3GB ExternalAppendOnlyMap is actually not released). The 1.6GB object is ExternalAppendOnlyMap (E2).

[Question]
Why the released ExternalAppendOnlyMap is still in memory?
The source code of ExternalAppendOnlyMap shows that the currentMap (AppendOnlyMap) has been set to null when the spill action is finished.

[Root cause in the source code] I further analyze the reference chain of unreleased ExternalAppendOnlyMap. The reference chain shows that the 3.3GB ExternalAppendOnlyMap is still referenced by the upstream/readingIterator and further referenced by TaskMemoryManager as follows. So, the root cause in the source code is that the ExternalAppendOnlyMap is still referenced by other iterators (setting the currentMap to null is not enough).

[Potential solution]
Setting the upstream/readingIterator to null after the forceSpill() action. I will try this solution in these days.
[References]
[1] PageRank source code. https://github.com/JerryLead/SparkGC/blob/master/src/main/scala/applications/graph/PageRank.scala
[2] Task execution log. https://github.com/JerryLead/Misc/blob/master/OOM-TasksMemoryManager/log/TaskExecutionLog.txt